
Avant le développement de l’imprimerie au XVe siècle, chaque manuscrit contenait un texte inédit. Même les « copies » montrent de nombreux changements plus ou moins significatifs. De fait, la rédaction de la Bible n’échappe pas à cette réalité et reflète des siècles de transmission avec plusieurs couches de révision et de rédaction, sans qu’on puisse définir le « premier auteur » d’un texte.
L'étude intitulée « Critical biblical studies via word frequency analysis: unveiling text authorship » (Études bibliques critiques par l’analyse de la fréquence des mots : dévoiler la paternité des textes), menée par Shira Faigenbaum-Golovin (Duke University), Alon Kipnis (Reichman University), Axel Bühler (Institut protestant de théologie de Paris, UMR 7192, hébergée au Collège de France), Eli Piasetzky (Tel Aviv University), Thomas Römer (Collège de France, UMR 7192) et Israel Finkelstein (University of Haifa), a cherché à utiliser les nouveaux outils algorithmiques concernant le langage pour identifier, caractériser et délimiter les textes écrits par différents groupes rédactionnels à l’intérieur de la Bible.
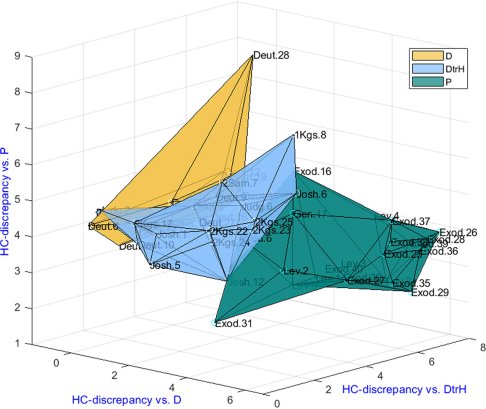
Cette étude s’est appuyée sur les résultats des philologues et des exégètes pour identifier des textes clés appartenant à différentes écoles de rédacteurs, puis l’algorithme a extrait et quantifié les mots et les suites de mots les plus importants. Cette première étape permet d’abord d’obtenir des réseaux sémantiques et ensuite d’observer spatialement la proximité et l’éloignement, en termes de langage, des différents milieux rédactionnels les uns des autres. Cette étape donne également la possibilité aux chercheurs de voir quelles sont les expressions majeures qui différencient une école de pensée d’une autre. Dans un second temps, par la statistique, des textes dont l’origine était débattue ont pu être attribués à l’un ou l’autre groupe rédactionnel.
Cet article ouvre la voie à d’autres études similaires exploitant les développements récents dans l’intelligence artificielle sur les modèles de langage pour en faire un outil au service des historiens de l’Antiquité.








